
DeepSeek, the Chinese language AI lab that just lately upended business assumptions about sector growth prices, has launched a brand new household of open-source multimodal AI fashions that reportedly outperform OpenAI’s DALL-E 3 on key benchmarks.
Dubbed Janus Professional, the mannequin ranges from 1 billion (extraordinarily small) to 7 billion parameters (close to the dimensions of SD 3.5L) and is on the market for fast obtain on machine studying and knowledge science hub Huggingface.
The biggest model, Janus Professional 7B, beats not solely OpenAI’s DALL-E 3 but additionally different main fashions like PixArt-alpha, Emu3-Gen, and SDXL on business benchmarks GenEval and DPG-Bench, in line with info shared by DeepSeek AI.
Its launch comes simply days after DeepSeek made headlines with its R1 language mannequin, which matched GPT-4’s capabilities whereas costing simply $5 million to develop—sparking a heated debate concerning the present state of the AI business.
The Chinese language startup’s product has additionally triggered sector-wide considerations it may upend incumbents and knock the expansion trajectory of main chip producer Nvidia, which suffered the most important single-day market cap loss in historical past on Monday.
DeepSeek’s Janus Professional mannequin makes use of what the corporate calls a “novel autoregressive framework” that decouples visible encoding into separate pathways whereas sustaining a single, unified transformer structure.
This design permits the mannequin to each analyze photographs and generate photographs at 768×768 decision.
“Janus Professional surpasses earlier unified mannequin and matches or exceeds the efficiency of task-specific fashions,” DeepSeek claimed in its launch documentation. “The simplicity, excessive flexibility, and effectiveness of Janus Professional make it a powerful candidate for next-generation unified multimodal fashions.”
In contrast to with DeepSeek R1, the corporate didn’t publish a full whitepaper on the mannequin however did launch its technical documentation and made the mannequin out there for fast obtain freed from cost—persevering with its follow of open-sourcing releases that contrasts sharply with the closed, proprietary method of U.S. tech giants.
So, what’s our verdict? Nicely, the mannequin is very versatile.
Nevertheless, don’t count on it to exchange any of essentially the most specialised fashions you like. It might generate textual content, analyze photographs, and generate pictures, however when pitted in opposition to fashions that solely do a type of issues nicely, at finest, it’s on par.
Testing the mannequin
Notice that there is no such thing as a fast approach to make use of conventional UIs to run it—Cozy, A1111, Focus, and Draw Issues are usually not appropriate with it proper now. This implies it’s a bit impractical to run the mannequin domestically and requires going by means of textual content instructions in a terminal.
Nevertheless, some Hugginface customers have created areas to strive the mannequin. DeepSeek’s official house will not be out there, so we suggest utilizing NeuroSenko’s free house to strive Janus 7b.
Concentrate on what you do, as some titles could also be deceptive. For instance, the House run by AP123 says it runs Janus Professional 7b, however as a substitute runs Janus Professional 1.5b—which can find yourself making you lose lots of free time testing the mannequin and getting dangerous outcomes. Belief us: we all know as a result of it occurred to us.
Visible understanding
The mannequin is nice at visible understanding and might precisely describe the weather in a photograph.
It confirmed an excellent spatial consciousness and the relation between completely different objects.
It’s also extra correct than LlaVa—the preferred open-source imaginative and prescient mannequin—being able to offering extra correct descriptions of scenes and interacting with the consumer based mostly on visible prompts.
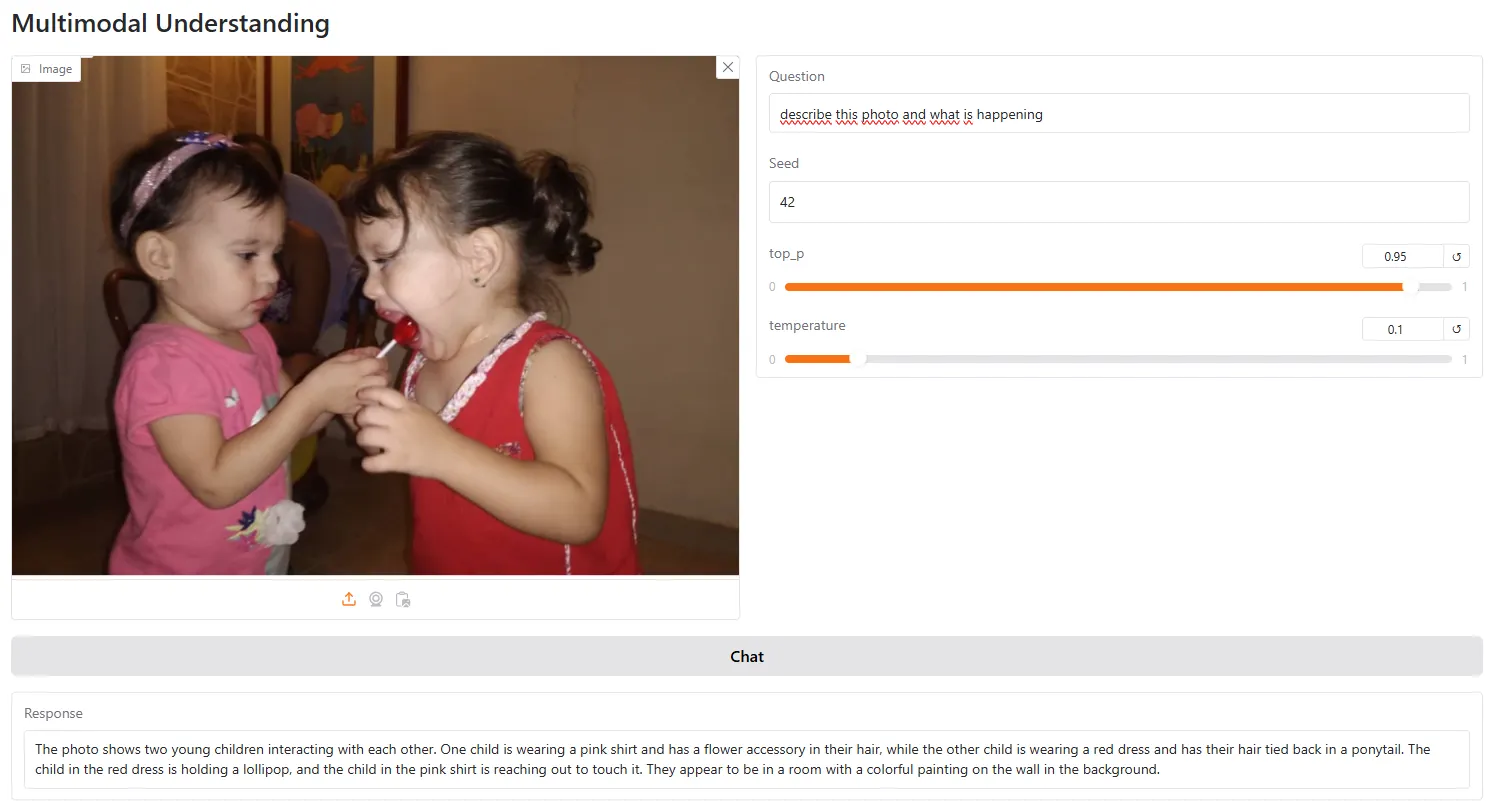
Nevertheless, it’s nonetheless not higher than GPT Imaginative and prescient, particularly for duties that require logic or some evaluation past what is clearly being proven within the photograph. For instance we requested the mannequin to investigate this photograph and clarify its message

The mannequin replied, “The picture seems to be a humorous cartoon depicting a scene the place a girl is licking the tip of a protracted purple tongue that’s hooked up to a boy.”
It ended its evaluation by saying that “the general tone of the picture appears to be lighthearted and playful, presumably suggesting a situation the place the lady is participating in a mischievous or teasing act.”

In these conditions the place some reasoning is required past a easy description, the mannequin fails more often than not.
However, ChatGPT, for instance, truly understood the which means behind the picture: “This metaphor means that the mom’s attitudes, phrases, or values are straight influencing the kid’s actions, notably in a adverse approach corresponding to bullying or discrimination,” it concluded—precisely, we could add.

A league of its personal
Picture technology seems sturdy and comparatively correct, although it does require cautious prompting to realize good outcomes.
DeepSeek claims Janus Professional beats SD 1.5, SDXL, and Pixart Alpha, nevertheless it’s essential to emphasise this should be a comparability in opposition to the bottom, non fine-tuned fashions.
In different phrases, the honest comparability is between the worst variations of the fashions at present out there since, arguably, no one makes use of a base SD 1.5 for producing artwork when there are lots of of wonderful tunes able to reaching outcomes that may compete in opposition to even state-of-the-art fashions like Flux or Steady Diffusion 3.5.
So, the generations are in no way spectacular by way of high quality, however they do appear higher than what SD1.5 or SDXL used to output after they launched.
For instance, here’s a face-to-face comparability of the pictures generated by Janus and SDXL for the immediate: A cute and lovable child fox with huge brown eyes, autumn leaves within the background enchanting, immortal, fluffy, shiny mane, Petals, fairy, extremely detailed, photorealistic, cinematic, pure colours.

Janus beats SDXL in understanding the core idea: it may generate a child fox as a substitute of a mature fox, as in SDXL’s case.
It additionally understood the photorealistic model higher, and the opposite components (fluffy, cinematic) had been additionally current.
That stated, SDXL generated a crisper picture regardless of not sticking to the immediate. The general high quality is healthier, the eyes are real looking, and the small print are simpler to identify.
This sample was constant in different generations: good immediate understanding however poor execution, with blurry photographs that really feel outdated contemplating how good present state-of-the-art picture mills are.
Nevertheless, it is essential to notice that Janus is a multimodal LLM able to producing textual content conversations, analyzing photographs, and producing them as nicely. Flux, SDXL, and the opposite fashions aren’t constructed for these duties.
So, Janus is much extra versatile at its core—simply not nice at something when in comparison with specialised fashions that excel at one particular process.
Being open-source, Janus’s future as a pacesetter amongst generative AI fans will rely on a slew of updates that search to enhance upon these factors.
Edited by Josh Quittner and Sebastian Sinclair
Typically Clever E-newsletter
A weekly AI journey narrated by Gen, a generative AI mannequin.








{kind=link}